인제대학교 의과대학 약리학교실
최근 ChatGPT와 같은 대형언어모델(Large LanguageModels; LLM)이 빠른 속도로 발전하여 문서작업, 아이디어 생성, 학습자료 검색 등의 다양한 곳에 활용되고 있다. 의학 데이터는 전자의무기록, 임상 보고서, 병리 보고서, 검사결과 등 다양한 출처로부터 생성되며, 이들 데이터 중 상당수는 비정형 텍스트 형태로 존재한다. 이러한 비정형 데이터는 분석 과정에서 구조화가 필요하며, 기존에는 이를 수작업으로 처리하거나 복잡한 자연어 처리 기법을 개별적으로 적용해야 했다. 방대한 텍스트 데이터를 바탕으로 자가지도학습 방식으로 훈련한 LLM은 복잡하거나 정형화되지않은 텍스트를 다룰 수 있어 이러한 문제를 해결하는 핵심적인 도구로 부상하고 있다.
비정형 데이터 처리에의 활용 비정형 텍스트에서 유용한 정보를 추출하는 것은 의료 데이터 기반의 연구에서 늘 겪는 어려움이다. 의무기록이나 병리, 영상 판독에는 다양한 약어, 오타, 비표준 용어가 혼재하고, 날짜나 단위 등도 일관성이 결여되는 경우가 빈번하다. LLM은 이러한 비정형 데이터를 정제하고, 개체명 인식(Named Entity Recognition), 관계 추출(Relationship Extraction), 텍스트 요약 등의 작업을 효과적으로 수행함으로써 기존에 연구자들이 오랜 시간을 들여 하나하나 검토하고 정리하던 작업을 자동화시키고 대량으로 처리하는 것을 가능하게 하고 있다(Goel et al., 2023; Truhn et al., 2024).
LLM의 뛰어난 언어 이해 능력은 비일관적인 날짜 형식 표준화나, 다국어 혼재 표현 처리, 의학적 약어 정규화와 같은 데이터 정제 과정에서 큰 이점을 제공한다. 기존의 경우의 수에 따른 정규표현식이나 조건문을 이용하는 방식으로는 예외상황을 처리할 수 없지만, “배가 아야야해요”와 같은 구어체로 적힌 글도 LLM을 이용하면 “복통”이라는 증상으로 정형화 가능하다. “RA”라는 약어를 맥락에 따라 류마티스관절염이나 우심방으로 표준화를 하거나, 단위가 누락된 경우 해당 검사 항목의 성격을 파악해 적절한 단위를 추론하는 것도 가능하다(Zhang et al., 2020; Kojima et al., 2022). 이처럼 전통적으로 많은 시간이 소요되던 전처리 과정을 자동화함으로써, 시간을 절약하고 더 대량의 데이터를 분석하는 것을 가능케한다.
LLM을 이용하여 환자의 의무기록 텍스트에 대해 초벌로 진단명이나 진단코드를 부여하는 것이 가능하고, 상당한 정확도를 보이고 있다(Ong et al., 2023). 이 밖에도 대량의 문헌 정보를 주제별로 자동 분류하여 특정 분야의 연구 동향을 파악하거나(Fijačko et al., 2024), 설문 응답의 감성분석(sentiment analysis)를 기존의 소프트웨어보다 정확하게 수행하는 등(Lossio-Ventura et al., 2024), 기존에는 사람이 수작업으로 분류하고 라벨을 붙이던 작업을 자동화하고 대량으로 분석하는 것을 가능하게 하고 있다.
LLM은 추출적 요약이 아닌 추상적(abstractive) 요약을 수행하여 단순히 원문 일부를 발췌하는 것이 아니라 새로운 문장으로 핵심 내용을 정리한다. 즉, 긴 문서에서 가장 중요한 정보를 추출하고 노이즈를 줄이는 역할을 할 수 있어, 요약을 거친 뒤 다양한 후속작업을 하는 방식으로 활용 가능하다. 조기 패혈증 예측 모델에 정형화된 데이터와 비정형 텍스트 데이터를 모두 활용하는 연구에서 의무기록을 그대로 엠베딩(텍스트의 의미를 내포한 숫자의 조합)으로 변환하는 것보다 요약문을 LLM으로 생성한 뒤 엠베딩으로 변환해 예측모델을 훈련시키는 것이 더 정확도가 높게 나오는것을 보인 연구가 있다 (Li et al., 2024). 또한 임상시험에 환자를 참여시킬 때 적합성 여부를 판단하는 AI모델을 만들때에도 LLM 기반으로 환자요약문(patient narrative)를 생성하고, 이어서 임상시험 선정 기준을 대조하여 판단하는 프로세스를 적용하는 방식으로도 활용 가능하다.
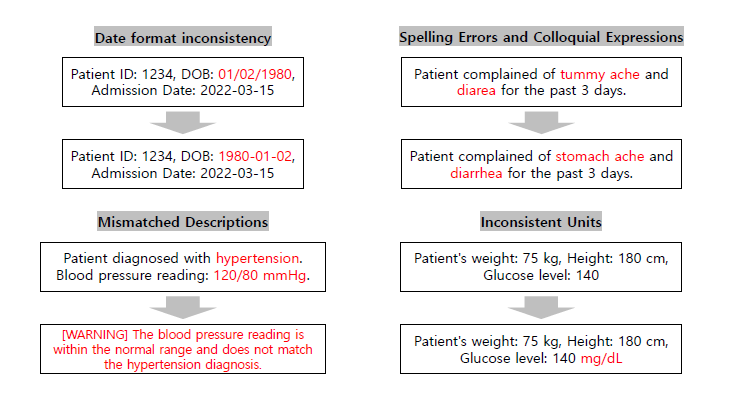 그림1
그림1
비정형 의료 데이터의 문제와 정제 과정. 날짜 형식 통일, 철자 및 구어체 표현 변환, 불일치 내용 확인, 단위 불일치 보정 등의 활용이 가능하다.
LLM은 단순히 데이터 정리와 추출에서 나아가, 두 개 이상의 텍스트 집단 간 차이점을 파악하고 이로부터 가설을 도출하는 작업에도 활용 가능하다. 예를 들어, A 약물과 B 약물을 투여받은 환자군 간에 보고되는 증상 차이를 파악하거나(Zhong et al., 2024), 학술지 투고 규정 내의 AI 관련 항목 유무를 식별하는 연구에서 LLM이 가설을 제안하고, 정성적 조건에 부합하는지 판단하는 등의 역할을 수행하여 AI 연구자와 인간 연구자가 협력하는 방식으로 연구 진행이 가능하다(Ahn, 2024). 이처럼 인간과 AI가 협업하는 방식의 연구가 점차 보편화될 것으로 기대된다(Hamer et al., 2023; Jin et al., 2023).
 그림2
그림2
가설 생성 및 텍스트 데이터 분석을 위한 인간-AI 협업 워크플로우. (A) 두 말뭉치 사이의 분포 차이를 기반으로 후보 가설을 LLM이 생성하고, 가설을 기반으로 데이터를 분석하는 접근.
(B) LLM이 분석 항목 제안을 생성하고, 인간 검토자와 LLM이 독립적으로 확인하여 일치도를 확인하는 접근.
최근 LLM 챗봇은 이용자의 명령에 따라 데이터 분석 코드를 R이나 python으로 작성해주는 수준을 넘어서 생성된 코드를 직접 가상환경에서 실행시키고 결과를 활용해 질문에 답해주는 요원(agent)와 같은 형태로 진화하고 있다. 예를 들어 ChatGPT의 코드 생성 및 실행 기능(Code Interpreter)를 활용하면 엑셀파일을 업로드하고 자연어 형태의 명령만으로 선형회귀 분석을 하고 산점도를 그리는 것이 가능하고, 더 나아가 데이터 분석의 방향성에 대한 조언을 구할 수도 있다. (Ahn 2023) 프로그래밍 언어나 통계 분석 방법론에 대한 숙련도가 낮은 비전문가도 손쉽게 “이 변수와 저 변수의 관계성을 확인할 수 있는 통계분석을 수행해줘”라고 명령하는 것으로 적절한 코드를 생성하고 실행 결과까지 얻는 일종의 자율주행처럼 데이터 분석 작업의 문턱을 낮추고 직접 참여할 수 있는 기회를 늘려줄 것이다.
다만 아직은 LLM을 데이터 분석에 활용하기 위해 LLM 서버에 데이터를 전송하고 결과를 받아오는 API 연동, 분석파이프라인 설계 등 기술적 역량이 요구된다. 특히 LLM이 정확하게 명령에 따라 동작할 수 있는 지시문을 잘 작성하는 ‘프롬프트 엔지니어링’은 학습과 훈련을 통한 숙달과정이 필요한 기술이고, 프롬프트에 따라 작업 결과물의 품질이나 정확도가 크게 달라질 수 있다(Bsharat et al., 2023). 이런 기술적 요구는 추후 수년간에 걸쳐 데이터 분석 전용 도구가 개발되고 유저 인터페이스가 발전하면서 해소되겠지만, 현재로서는 사전 지식 없이 바로 LLM을 활용한 분석을 하기에는 무리가 있는 상황이다.
LLM이 수행한 분석 결과에 대한 신뢰성 확보를 위해서는 정답률을 측정하거나 인간 연구자가 수행한 분석결과와 LLM의 결과를 교차 검증하는 절차가 필요하다. 대규모 데이터셋 중 일부를 추출해 인간 전문가와 LLM이 독립적으로 분석한 뒤 결과를 비교함으로써, LLM 사용의 타당성을 확보할 수 있다. 또한, LLM은 랜덤성이 내재되어 있어 같은 명령을 똑같이 수행해도 다른 결과가 나올 가능성이 있다. 이런 랜덤성은 아이디어를 생성하는 류의 작업에는 창의성을 높이는 긍정적인 효과가 있지만, 분석에 활용하는 경우에는 걸림돌이 될 수 있다. 체계적으로 반복측정해 확률이나 신뢰구간을 측정하는 신중한 접근이 필요하다. 이렇게 측정된 성능 및 정확도를 바탕으로 연구 전체의 분석 파이프라인 설계를 해야 신뢰성이 있는 결과를 얻을 수 있다.
일반적으로 인공지능을 활용한 예측은 결과가 정확하더라도 그 의사결정 과정을 알기 어려워 불투명한 블랙박스에 비유되곤 한다. 그러나 LLM의 경우 ‘expand-guess-refine’와 같은 프롬프트 전략을 사용하면 모델이 추론 과정을 단계별로 제시하도록 유도할 수 있다(Manathunga & Hettigoda, 2023; Savage et al., 2024). 이는 임상의의 사고 프로세스를 모델 출력을 통해 재현함으로써 결과에 대한 신뢰도를 제고할 수 있을 뿐 아니라 생각의 사슬(Chain of thought) 방식으로 결과를 생성함으로써 추론 결과의 정확도를 높이는 효과도 얻을 수 있다.
환자 데이터는 민감한 개인정보를 포함하기 때문에, 제3자 서비스로 전송되는 LLM 기반 분석에는 보안 문제가 뒤따른다. 이를 극복하기 위해 연구자의 기기 또는 외부와 단절된 사내 네트워크에서 작동하는 LLM을 활용하거나, 신중한 비식별화 과정을 거치는 것을 검토해야 한다. 또한 LLM은 확률적 성격과 모델 업데이트에 따라 결과가 달라질 수 있어 재현성 관리가 중요하다. 오픈소스 모델 활용, 프롬프트 및 결과 로그 관리, 모델 버전 고정 등이 연구의 재현성을 높이는 전략이 될 수 있다. 이러한 노력은 LLM 활용이 안정적이고 신뢰성 있는 연구 수단으로 자리매김하기 위한 핵심 요소이다.
이와 같이 LLM은 의학 분야에서 비정형 텍스트 데이터 분석을 자동화하고 고도화할 수 있는 수단으로 떠오르고 있다. 기존의 연구가 검사 수치와 같은 정형화된 데이터에 집중해 분석해왔다면, 앞으로는 더욱 적극적으로 환자와의 문진 내용, 수술 과정의 음성 기록, 환자가 스스로 증상을 기록한 일지와 같은 비정형 텍스트를 수집하고 분석하고 활용하는 방향으로 패러다임이 변화할 것이다. 다만 이 과정은 다양한 기술적 요구, 정확도 검증, 해석 가능성 확보, 개인정보 보호, 재현성 관리 등의 과제 해결이 필수적이며, LLM 성능의 진보와 함께 이들 문제가 해결됨에 따라 의료 데이터 연구에서 LLM의 역할은 더욱 확대될 것으로 기대한다.1
[References]
1. Ong J, Kedia N, Harihar S, Vupparaboina SC, Singh SR, Venkatesh R, et al. Applying large language model
artificial intelligence for retina International Classification of Diseases (ICD) coding. Journal of Medical
Artificial
Intelligence 2023;6.
2. Goel A, Gueta A, Gilon O, Liu C, Erell S, Nguyen LH, et al. LLMs Accelerate Annotation for Medical
Information
Extraction. In. Machine Learning for Health (ML4H): PMLR, 2023:82-100.
3. Truhn D, Loeffler CM, Müller-Franzes G, Nebelung S, Hewitt KJ, Brandner S, et al. Extracting structured
information from unstructured histopathology reports using generative pre-trained transformer 4 (GPT-4).
The Journal of Pathology 2024;262:310-9.
4. Zhang H, Dong Y, Xiao C, Oyamada M. Large language models as data preprocessors. arXiv [preprint].
2308.16361; https://doi.org/10.48550/arXiv.2308.16361
5. Kojima T, Gu SS, Reid M, Matsuo Y, Iwasawa Y. Large language models are zero-shot reasoners. Advances in
neural information processing systems 2022;35:22199-213.
6. Fijačko N, Creber RM, Abella BS, Kocbek P, Metličar Š, Greif R, et al. Using generative artificial
intelligence
in bibliometric analysis: 10 years of research trends from the European Resuscitation Congresses.
Resuscitation
Plus 2024;18:100584.
7. Lossio-Ventura JA, Weger R, Lee AY, Guinee EP, Chung J, Atlas L, et al. A Comparison of ChatGPT and Fine-
Tuned Open Pre-Trained Transformers (OPT) Against Widely Used Sentiment Analysis Tools: Sentiment
Analysis of COVID-19 Survey Data. JMIR Mental Health 2024;11:e50150.
8. Li Q, Ma H, Song D, Bai Y, Zhao L, Xie K. Early prediction of sepsis using chatGPT-generated summaries
and
structured data. Multimedia Tools and Applications 2024:1-23
9. Hamer DMd, Schoor P, Polak TB, Kapitan D. Improving Patient Pre-screening for Clinical Trials: Assisting
Physicians with Large Language Models. arXiv [preprint]. 2304.07396; doi: https://doi.org/10.48550/arXiv.
2304.07396
10. Jin Q, Wang Z, Floudas CS, Sun J, Lu Z. Matching Patients to Clinical Trials with Large Language Models.
arXiv [preprint]. 2307.15051; doi: https://doi.org/10.48550/arXiv.2307.15051
11. Zhong R, Zhang P, Li S, Ahn J, Klein D, Steinhardt J. Goal driven discovery of distributional
differences via
language descriptions. Advances in Neural Information Processing Systems 2024;36.
12. Ahn S. Large language model usage guidelines in Korean medical journals: a survey using human-artificial
intelligence collaboration. Journal of Yeungnam Medical Science [accepted]. doi: https://doi.org/10.12701/
jyms.2024.00794
13. Ahn S. Data science through natural language with ChatGPT’s Code Interpreter. Transl Clin Pharmacol.
2024 Jun;32(2):73-82. doi: 10.12793/tcp.2024.32.e8.
14. Bsharat SM, Myrzakhan A, Shen Z. Principled Instructions Are All You Need for Questioning LLaMA-1/2,
GPT-3.5/4. arXiv [preprint]. 2312.16171; doi: https://doi.org/10.48550/arXiv.2312.16171
15. Manathunga S and Hettigoda I. Aligning large language models for clinical tasks. arXiv [preprint].
2309.02884; doi: https://doi.org/10.48550/arXiv.2309.02884
16. Savage T, Nayak A, Gallo R, Rangan E, Chen JH. Diagnostic reasoning prompts reveal the potential for
large
language model interpretability in medicine. npj Digital Medicine 2024;7:1-7.
